-
 Frank Neff
Frank Neff
- 02 Mar, 2018
Using Shapeless for Data Cleaning in Apache Spark
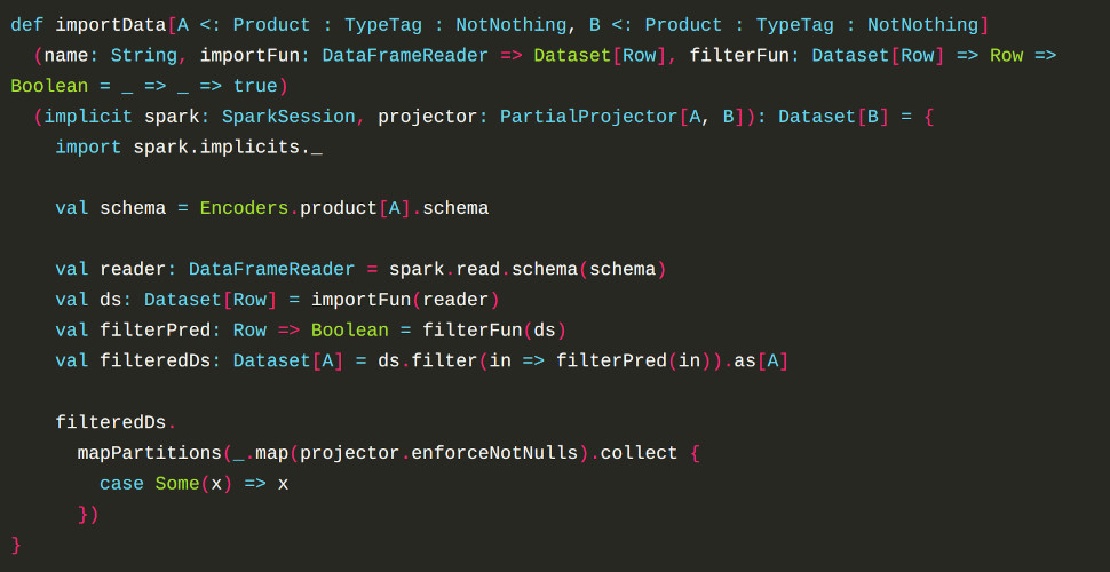
When it comes to importing data into a BigData infrastructure like Hadoop, Apache Spark is one of the most used tools for ETL jobs. Because input data – in this case CSV – has often invalid values, a data cleaning layer is needed.Most tasks in data cleaning are very specific and therefore need to be implemented depending on your data, but some tasks can be generalized…
Read More