When it comes to importing data into a BigData infrastructure like Hadoop, Apache Spark is
one of the most used tools for ETL jobs. Because input data
– in this case CSV – has often invalid values, a data cleaning layer is needed.Most tasks in data cleaning
are very specific and therefore need to be implemented depending on your data, but some tasks can be generalized…
In this post, I’ll not go into Spark, ETL or BigData in general, but provide one approach to clean null / empty values
off a data set. This can be used in virtually any Scala project, Spark data-cleaning is only a nice use case to
demonstrate it.
The Problem
To describe the problem which needs to be solved, let’s say that we have a Stream of case objects as input. Some
optional values in the input case class must be present, so we transform a Stream[A] to a Stream[B] where B is a
new case class which contains the same values but maybe not optional:
case class A(normal: String, mandatory: Option[String], opt: Option[String])
case class B(normal: String, mandatory: String, opt: Option[String])
def transform(a: A): Option[B] = ???
val importStream: Stream[A] = ???
val cleaned = importStream.flatMap(transform)
So far, so good. The mandatory field exists in both classes, but in the result B it is not optional. As one can see,
the transform function returns an Option[B], which should be None if one of those “mandatory” fields has no value.
In that tiny example, the transform method can just be implemented using a simple for-comprehention:
def transform(a: A): Option[B] = for {
mandatory <- a.mandatory
} yield B(a.normal, mandatory, b.opt)
The Generic Approach
The later transform implementation is very simple and straight forward. That said, nothing speaks against that
specific implementation. If you only need this at a single point, and for a more or less small class, stop reading here
and use the for-comprehention.
But… Depending on the data, such case classes can be way bigger, having like 50 properties. Or one needs to transform
50 different classes. In that case, a generic function like the following becomes very handy:
def enforceNotNulls[A, B](a: A): Option[B]
Because every case class implements Product, the HList of the Shapeless
library can be utilized to do transformations on them. For an example, a trait called PartialProjector is defined:
import shapeless.{::, Generic, HList}
trait PartialProjector[A, B] extends Serializable {
def enforceNotNulls(a: A): Option[B]
}
This trait must now be implemented for all types which can be transformed. We’ll use Scalas implicit resolution
afterwards to find the right function for the type to be transformed and call them recursively. To start with a simple
example, an identProjector instance is implemented, which just maps all input types to options:
object PartialProjector extends LowPrioInstances {
def instance[A, B](f: A => Option[B]): PartialProjector[A, B] = new PartialProjector[A, B] {
override def enforceNotNulls(a: A): Option[B] = f(a)
}
implicit def identProjector[A]: PartialProjector[A, A] = new PartialProjector[A, A] {
override def enforceNotNulls(a: A): Option[A] = Option(a)
}
def apply[A, B](implicit partialProjector: PartialProjector[A, B]): PartialProjector[A, B] = partialProjector
}
This example is already usable for simple types like strings:
PartialProjector[String, Option[String]]("foo") // Some("foo")
PartialProjector[String, Option[String]](null) // None
As already mentioned, the apply[A,B] method of the PartialProjector object uses implicit resolution to find a
fitting implementation of the trait for the given type A. The instance function is just a helper to instantiate the
PartialProjector trait. Because there is only one implicit (the identProjector) which fits every type, results will
always be Some(A) unless input is null.
Implementation for Specific Types
As a next step, specific types must be implemented. If, for example, an Option(String) is transformed, the result
should not be Some(Some(String)), but Some(String). To achieve that, a second implicit for option types needs to be
implemented:
trait LowPrioInstances {
implicit def identProjector[A]: PartialProjector[A, A] = new PartialProjector[A, A] {
override def enforceNotNulls(a: A): Option[A] = Option(a)
}
}
object PartialProjector extends LowPrioInstances {
def instance[A, B](func: A => Option[B]): PartialProjector[A, B] = new PartialProjector[A, B] {
override def enforceNotNulls(a: A): Option[B] = func(a)
}
implicit def optProjector[A]: PartialProjector[Option[A], A] = instance {
case Some(x) => Option(x)
case None => None
}
def apply[A, B](implicit partialProjector: PartialProjector[A, B]): PartialProjector[A, B] = partialProjector
}
First of all, because the identProjector matches every given type, it was moved to a parent trait LowPrioInstances.
As the name suggests, this implicit will only be used, if none in PartialProjector matches. Also, there is a new
implicit optProjector which handles Option[Any] types.
Case Classes
To transform case classes, first of all, an implicit for HLists (which is used to generically represent case classes) is
needed:
implicit def hConsProjector[H, H0, T <: HList, T0 <: HList](implicit
hProjector: PartialProjector[H, H0],
tProjector: PartialProjector[T, T0]): PartialProjector[H :: T, H0 :: T0] = instance(
hList => {
for {
h <- hProjector.enforceNotNulls(hList.head)
t <- tProjector.enforceNotNulls(hList.tail)
} yield h :: t
}
)
Because a HList has a head and a tail (like Scala lists), the hConsProjector uses two implicits. The first
hProjector is an instance to transform the head element. This could e.g be of type String or Option[Int], etc. The
second one, tProjector, is an instance to transform the tail, which is another HList. So this will resolve to
hConsProjector which is simply a recursive call. For the last, empty tail element (HNil), one could write a
hNilProjector, but the identProjector already handles this correctly, so we don’t need one.
Now that the PartialProjector can handle HLists, one more implicit is needed to transform case classes:
implicit def cClassProjector[CC1, CC2, Repr1, Repr2](implicit
gen1: Generic.Aux[CC1, Repr1],
gen2: Generic.Aux[CC2, Repr2],
projector: PartialProjector[Repr1, Repr2]): PartialProjector[CC1, CC2] = instance(
cc1 => {
projector.enforceNotNulls(gen1.to(cc1)).map(gen2.from)
}
)
This function takes an implicit for generic representations of source and target case classes (gen1 and gen2).
The third generic is aprojector to transform the generics, which will resolve to hConsProjector. The method
derives an HList from the input case object, runs the transformation on it and instanciates the target case class from
the transformation result.
Usage
The PartialProjector can now be used like the generic function transform[A,B] in the problem definition to enforce
not null / None elements in case classes:
case class A(normal: String, mandatory: Option[String], opt: Option[String])
case class B(normal: String, mandatory: String, opt: Option[String])
def in1 = A("foo", Some("bar"), Some("baz"))
def in2 = A("foo", None, Some("baz"))
def res1: Option[B] = PartialProjector[A, B].enforceNotNulls(in1) // Some(B("foo", "bar", "baz"))
def res2: Option[B] = PartialProjector[A, B].enforceNotNulls(in2) // None
But Spark…
I used some glue-code is SPark to make things easier. The following will load CSV data from HDFS, create a DataSet[A]
and transform it to a DataSet[B]:
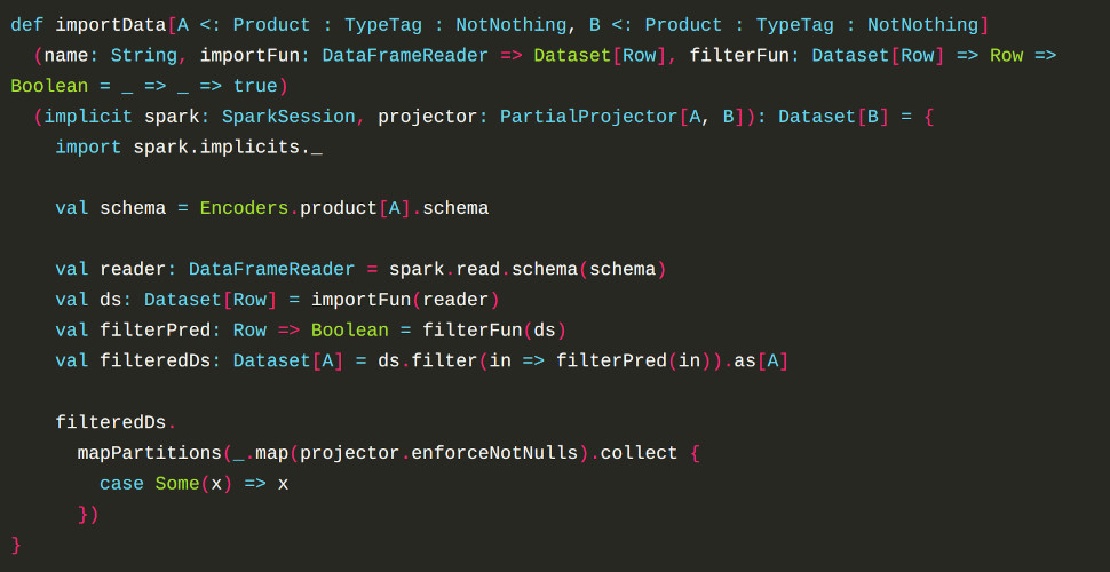
def importData[A <: Product : TypeTag : NotNothing, B <: Product : TypeTag : NotNothing]
(name: String, importFun: DataFrameReader => Dataset[Row], filterFun: Dataset[Row] => Row => Boolean = _ => _ => true)
(implicit spark: SparkSession, projector: PartialProjector[A, B]): Dataset[B] = {
import spark.implicits._
val schema = Encoders.product[A].schema
val reader: DataFrameReader = spark.read.schema(schema)
val ds: Dataset[Row] = importFun(reader)
val filterPred: Row => Boolean = filterFun(ds)
val filteredDs: Dataset[A] = ds.filter(in => filterPred(in)).as[A]
filteredDs.
mapPartitions(_.map(projector.enforceNotNulls).collect {
case Some(x) => x
})
}
NotNothing
As you may notice, the type arguments need some extra magic, because not all types can be transformed. Given types must
implement Product for generic derivation, TypeTag so their type can be determined and finally NotNothig. The later
is needed to prevent Nothing bottom type inference. More info about that “type inference hack” can be found in the
hacking-scala.org article or
just google “NotNothing”:
import scala.annotation.implicitNotFound
@implicitNotFound("Sorry, type inference was unable to figure out the type. You need to provide it explicitly.")
trait NotNothing[T]
object NotNothing {
private val Evidence: NotNothing[Any] = new Object with NotNothing[Any]
implicit def notNothingEv[T](implicit n: T =:= T): NotNothing[T] = Evidence.asInstanceOf[NotNothing[T]]
}
Examples
The importData function makes CSV loading very easy and keeps stuff generic. A simple example call will look like
this:
case class RawGroup(id: Option[String], isActive: Option[Boolean], description: Option[String])
case class Group(id: String, isActive: Boolean, description: Option[String])
val import1: DataSet[Group] = importData[RawGroup, Group]("groups", _.
option("header", "true").
csv("/data/some.csv").
withColumnRenamed("Strange col N4m€", "colName").
filter("colName is not null"))
As you may noticed, an additional filter function can be passed, which becomes handy in some cases like filtering
duplicates:
val import2: DataSet[User] = importData[RawUser, User]("doctors", _.
option("header", "true").
option("delimiter", ";").
csv("/data/user_*.csv"), rawUsers => {
import spark.implicits._
val duplicateUserIds = rawUsers.
groupBy("userId").count.
filter($"count" > 1).
map(x => x.getAs[Long]("userId")).
collect.toSet
row => duplicateUserIds.contains(row.getAs[Long]("userId"))
})
}
When reading CSV-data to typed DataSet[T], Option[_] fields on nullable columns produce None values, as expected.
Sometimes… But under certain conditions – which I am not able to further explain because I don’t know –
values can be Some(null) which is basically a fever nightmare when trying to clean up dirty data…
That problem can be solved by implementing another implicit to transform Some(null) to None. But because the
implementation will propagate None values, we need to return Some(None) instead of just None. Otherwise, all
transformations on case classes containing Option types will result in None instead of Option[B]:
implicit def optOptProjector[A]: PartialProjector[Option[A], Option[A]] = instance {
case Some(x) => if (x != null) Some(Some(x)) else Some(None)
case None => Some(None)
}
Note to myself: I suck at naming things
Fat-Jars
If you build a fat jar using SBT assembly, which is common for Spark-jobs, please don’t forget to shade the dependent
shapeless library, because spark also uses shapeless internally which may conflict otherwise.
Limitations
Because the transformation depend on the order of properties and not their labels, input and output case classes
(A and B) must have the same number of properties in the same order. Of course it is also possible to build the
HLists from labelled generics, so the properties with the same name would be mapped. I personally prefer mapping them by
order, because by using this variant, properties can also be renamed during transformation.

 Frank Neff
Frank Neff
